
Envisioning a New Approach to Geodata Processing

This is a recap of my work and the subsequently gained learnings of the last two years. Parts of it have been discussed in my talks on FOSSGIS and SOTM conferences, previous blog posts or podcasts.
Today
Processing geo data can be approached in two ways: Either the algorithm is already clear and the process can be automated and data can be processed directly, or: a human element is needed for processing in some kind of exploratory phase.
There are processes which are somewhere in between, because they are generally application driven, but need human interaction in some step, e.g. generalization, in which a human preprocesses geometries, but can later pass those into an automated pipeline which will use those for e.g. low resolution purposes.1
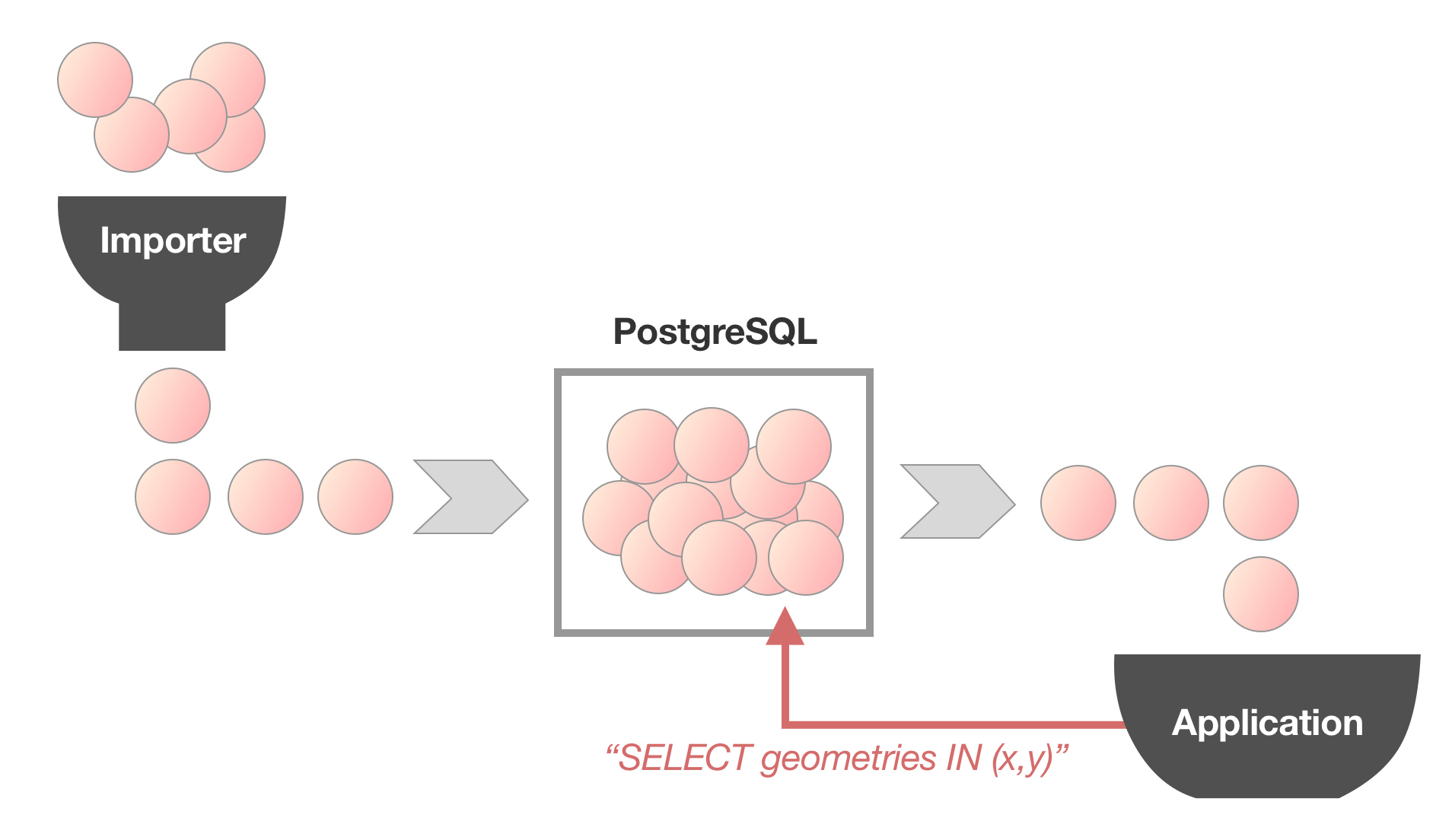
Manual processing is especially present in the traditional geospatial work: Surveying, spatial analysis and print maps. This is most often done using desktop GIS applications, like QGIS. For persistence either shapefiles or a local PostgreSQL/PostGIS database are used frequently.
Automated processes very often have PostGIS at its core, too. Projects like OpenMapTiles even use a Postgres database to import all data first just to retrieve all data from it after that.

For manual processes computational performance is seemingly not very important. Operations controlled by humans are often the limiting factor. Nonetheless in larger data sets it can become tedious when loading pauses become noticeable: Speaking from past personal experience, waiting for Tilemill to rerender the current view after a minor change can be very stressful and slow down any iterative development.
Automated processes often have very different characteristics, because they generally involve much larger data sets and mostly require a sequential processing of all present data. Typically those are workloads which are not suitable for a full relational database system.
Graphical map making is, as mentioned before, a mixture: Often large data set, but with a manual element. Especially in early stages, when a complete style needs to be designed, a lot of iterations may be needed, so low latency is necessary. Later on, throughput is much more important, which probably is the reason for the increasingly large popularity of vector tiles, because it offers both benefits: Low barrier for style changes while being very easy to scale.
Spatial awareness is less important than it might seem for a lot of applications: Layers or other categorizations of features need to be considered, too, which often lead to a full read and write cycle: Every feature needs to be retrieved and read to be written. For such workflows, ACID semantics which are present in database suites are not needed.
Also, big data sets are coming along: They are large enough to overflow available memory, but generally still small enough to be persisted on a single disk/machine.
Sharing data sets can often be a large pain point: If sharing a central PostGIS is not feasible (e.g. because of too high latency or firewall and policy restrictions), passing on data can hinder collaboration: Shapefiles are severely limited, spatialite is too slow for large-ish data sets and shipping off a complete PostgreSQL cluster can be quite difficult, especially for non-programming users.
On the other side of the fence
Aside from classical geo spatial work (like in government agencies) and neo-geographers (like OpenStreetMap contributors) a third class of users with geospatial needs have emerged: Companies which develop products like location based services or social networks, which are not in the tradition of using GIS tooling. They use software that is suitable to their existing toolkit, programming environment and scale. They generally do not participate in standardization, but rather stay in their own ecosystem.
While generally geospatial data sets are comparatively small in contrast to user data, some organizations prefer to shard it across nodes and make additional steps to make data more available.
Trends
Using tiles is not a new concept2: They have been introduced when web-based maps have been brought to the public. There is no need to download the whole data set, just to have a look at a geographical context of a few street blocks.
With the inception of vector tiles, the same mechanism of reducing data delivery to small spatially index files has been adapted into a wide variety of applications: The obvious map rendering in browsers3, but also routing on tiles4 and even geocoding5. Generally, engineers in VC funded companies seem to enjoy to build distributed toolchains in order to generate vector tiles.
Also, more and more applications have an initial import stage, in which they transform all available data using domain specific application logic to be able to operate.6
In-Process Recap
- Automated geo data processing suffers from performance bottlenecks: Especially during development this can be tedious. Databases have a lot of nice characteristics, of which a lot is not needed for geospatial work.
- Distributed processes have huge performance impact (read: dozens of instances working on days for a planet-sized data set)7
- Not everyone is able to process worldwide/planet OpenStreetMap data on their own machine (OSM full planet needs >40 GB RAM).
- The power of OSM comes from grassroot approach, not from large comities!
How to Make Everyone Happy
It becomes clear that there is a need for a resource efficient approach, which solves common problems. Computers have become very fast for some classes of problems while other things are still rather slow. Generally speaking sequential processing of similar data has become very fast: with heavily-pipelined CPU cache architectures, the spread of GPU based processing or very efficient JIT systems. If embraced, we could benefit from huge performance gains by eliminating expensive index traversals and memory seeking.
It needs to be possible that users can use data sets in their desktop GIS software while being able to write scripts or programs that can process those very efficiently – optimally in the programming language of their choice, while being able to interact with other software.
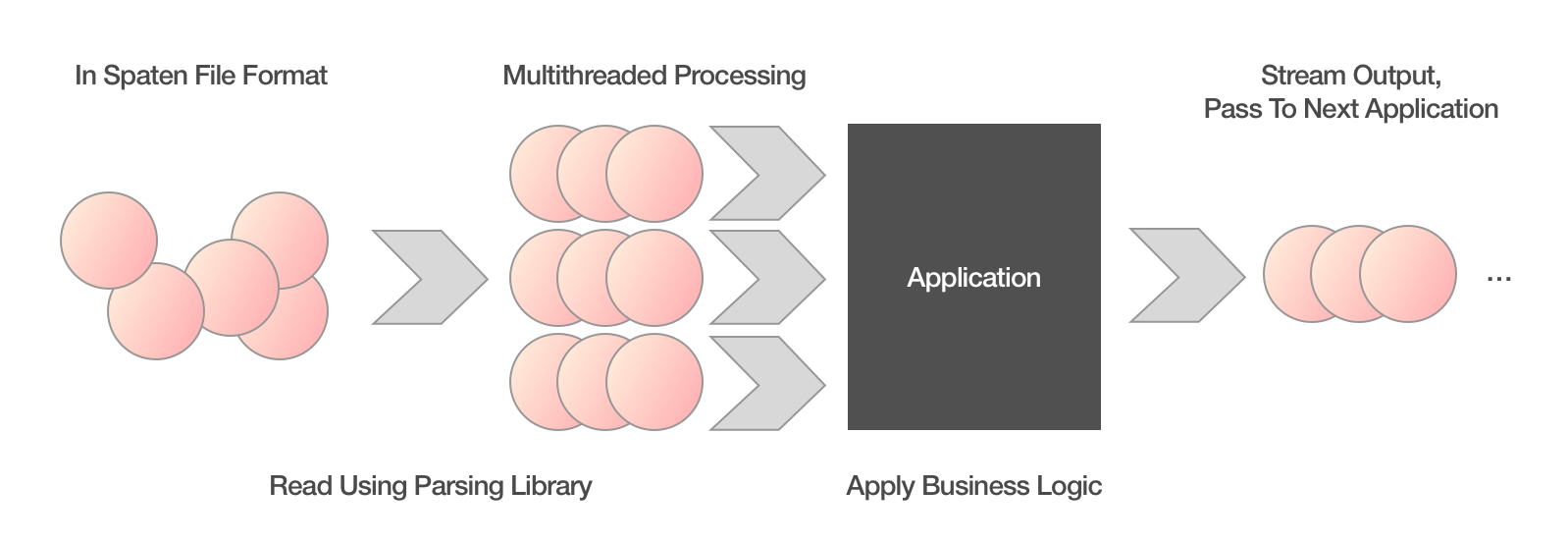
By the help of good libraries in diverse programming environments it is possible to construct an approach of stream in, stream out: Every written application takes a stream of spatial features, processes each one by one (or optionally multi-threaded using workers) and returns the output as a stream. Thus an application needs only a fraction of the memory that a full data set would require. From there on, only the speed of the CPU, the number of cores and the complexity of the applied algorithm would limit the performance.
Use Cases
Let’s have a look on different use cases (in a simplified way) and judge how they could fit into such a mode of operation:
- Multilingual maps (transliteration/transcription)
- Work steps:
- Traverse every feature
- Look at location
- Look at name tags
- Return every feature with appropriately transformed name
- Work steps:
- Tiled maps (e.g. vector tiles)
- Work steps:
- Traverse every feature
- Look at location
- Determine affected tile
- Append geometries to appropriate tiles
- Work steps:
- Data analysis
- Work steps are very dependent on the use case, but data sets are mostly not that large and can be scanned more efficiently than indexed and retrieved on every operation. Especially volatile data has a bad index utilization.
- When multiple people are involved, a shared DB can make more sense
- Also: PostGIS offers a lot of intuitive tools for processing
- Geocoding
- Geocoding software like nominatim has special importers, which have to process every feature on initialization, but mostly do not rely on a spatial database.
- Scanning every feature and applying an algorithm is already exercised.
For multilingual maps, tiled maps or geocoding the streamed approach is pretty natural and could be applied in an efficient manner. For data analysis, it depends on the task and the people involved. Especially in exploratory phases, a database that allows concurrent access might be useful.
Limitations and Obstacles
Of course adoption needs aside from strong benefits also a reduced set of obstacles, but obviously not everyone is incentivized or motivated to switch to a new paradigm which is a hindrance on its own. Aside that non-programmers still want to use their GUI software without much change. When loading times improve or the friction of exchanging files gets reduced users might notice, but missing features or changes in the daily workflow will be much more painful. After all, almost no-one complains about a coffee break while the computer is busy.8
PostGIS power users will probably never switch: They are used to a very specific declarative mind set, which is so wildly different that friction might always outweigh the speed or convenience benefits. Also, enterprise users will probably not consider switching before everything is standardized.
When specifically considering an implementation of this approach and looking at the most probable reason why most software uses PostGIS as a geospatial toolkit, it seems that the majority of spatial libraries are of poor quality and correct handling of complex geometries is tricky, even with the support of specialized packages.
Opportunities
This novel approach should not only cover existing use cases, but also bring new opportunities to the table: Hobbyists should be enabled to process worldwide data sets on their local computers (or on small, cheap cloud instances, if you prefer). Furthermore applications could start being decoupled from a specific database implementation, e.g. CartoCSS projects contain inline SQL queries9, which makes them not only not portable to other databases, but also generates a significant effort when trying to port it to a different table schema.
The Suggestion
To recap, we should treat geo data as a stream of features that can be passed from application to application in an efficient manner. The same format to pass features should also be used for persistence on disk or sharing using the cloud. To pass data between applications, pipes can be used, reducing disk footprint and enabling more agile processing.
This train of though is encapsulated into the Spaten file format, which I suggest as a basis for pipeline processing. This format is already used in the Grandine tools.
State of the Vision
A foundation has been laid: The format for serializing features has been defined and a first library implementation in Go is available for integration. This is used in the Grandine toolset in order to pass streams in and out, where applicable:
grandine-tilercan build vector tile sets from streamsgrandine-spatializeconverts OpenStreetMap into a spatial format, serializing it as a Spaten streamgrandine-converterreads geojson and can stream out Spaten data
In discussions at conferences, meetups and hack days there is a general interest in the technology and some people are willing to have a deeper look or integrate Spaten into their software in the future.
How can you help?
Of course this is just a first step into the journey. I think a lot of applications and people can benefit from a faster, more efficient toolchain. I strongly believe, we can make open applications more cooperative and make tools written in different environments and languages more useful to everyone.
But for that I need your help: Tell me, what you are up to. Write an email, talk to me at some event. You can also help test the existing libraries and command line tools. If you find bugs, write an email or file an issue. Also fuzzing or expanding benchmarks and tests would be great. Go experts can help me write a better polygon clipping function.
I am also looking for people willing to help out build serialization libraries for more programming languages (especially JavaScript/node.js and C). If you are interested, let’s work together!
Also if you want your company be part of this, you can make me work for you as a freelancer.
Acknowledgments
Special thanks to the Prototype Fund, the Open Knowledge Foundation Germany and German Ministry of Education and Research, who supported the project and funded six months of development.
Also all of this would not have been possible without Jochen Topf, who convinced me not to jump into the Postgres rabbit hole again and supported a lot of initial thought.
In the end I wouldn’t have come so far if not for the great conversations I had with people from the OpenStreetMap universe: If you have ever written an email, talked to me or just listened to my insane ideas: Thank you, you have been a great motivator!
-
OpenStreetMapData provides generalized coastlines for use in low zoom levels. ↩︎
-
OSGeo already published TMS in 2006 ↩︎
-
OSRM needs to extract the road network from source files before being able to run ↩︎
-
Approaches like OpenMapTiles need days to process a full OpenStreetMap planet. ↩︎
-
Example from OpenStreetMap CartoCSS code repository ↩︎