
Keeping your OpenStreetMap Database Replicated
The physical world is changing all the time, and so is OpenStreetMap (OSM). Luckily, you can just tap the source by using the replication system. osm2pgsql can import your OSM data into PostgreSQL and also update from that replication stream.1
If you want to scale out your database because you want capacity and/or redundancy, you need a strategy to orchestrate this process. One option is to run the import and update process on each Postgres node.
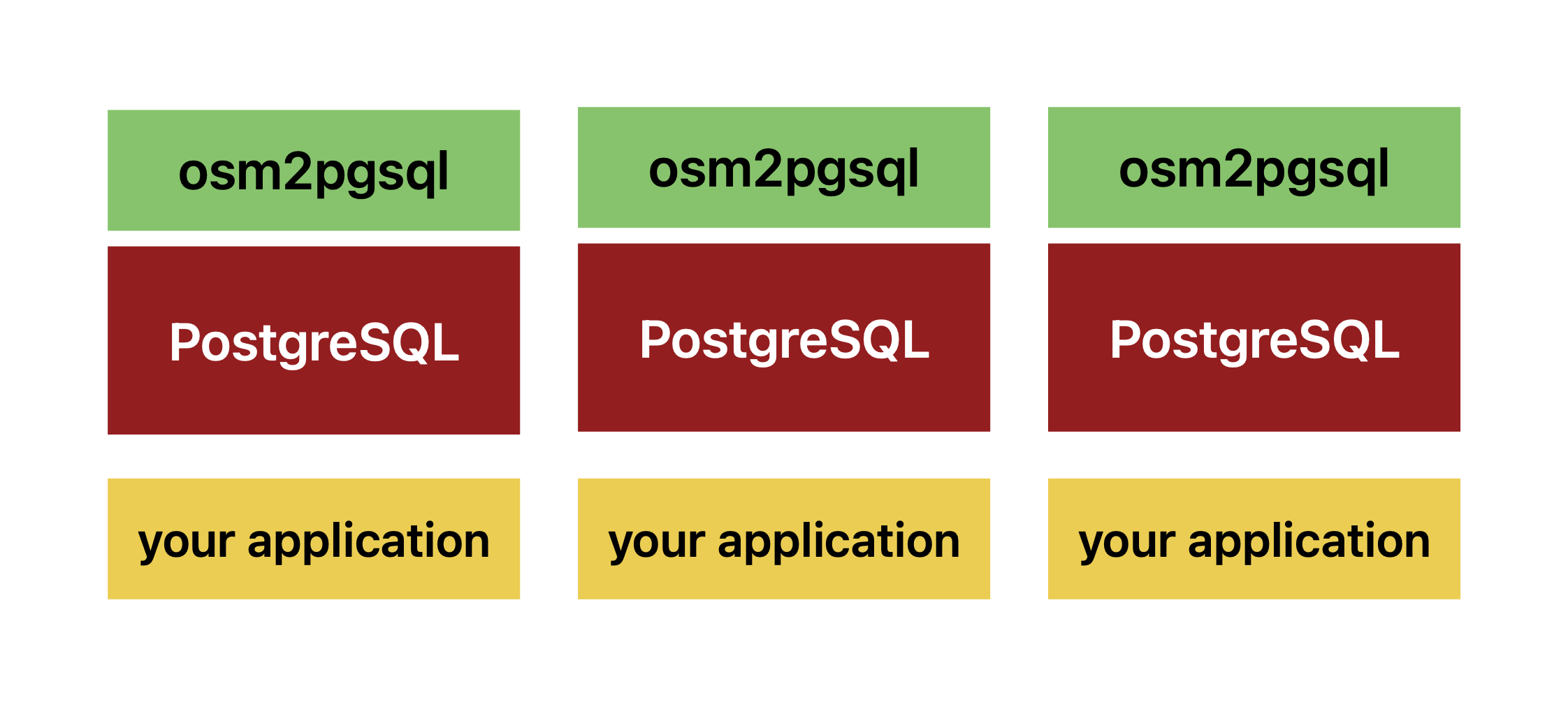
This has multiple drawbacks: due to the unique way the OpenStreetMap data format is structured, you need to keep a large state file to be able to update your imported database on each node.2 Also, the update process itself is quite resource-intensive.
One importer, multiple replicas
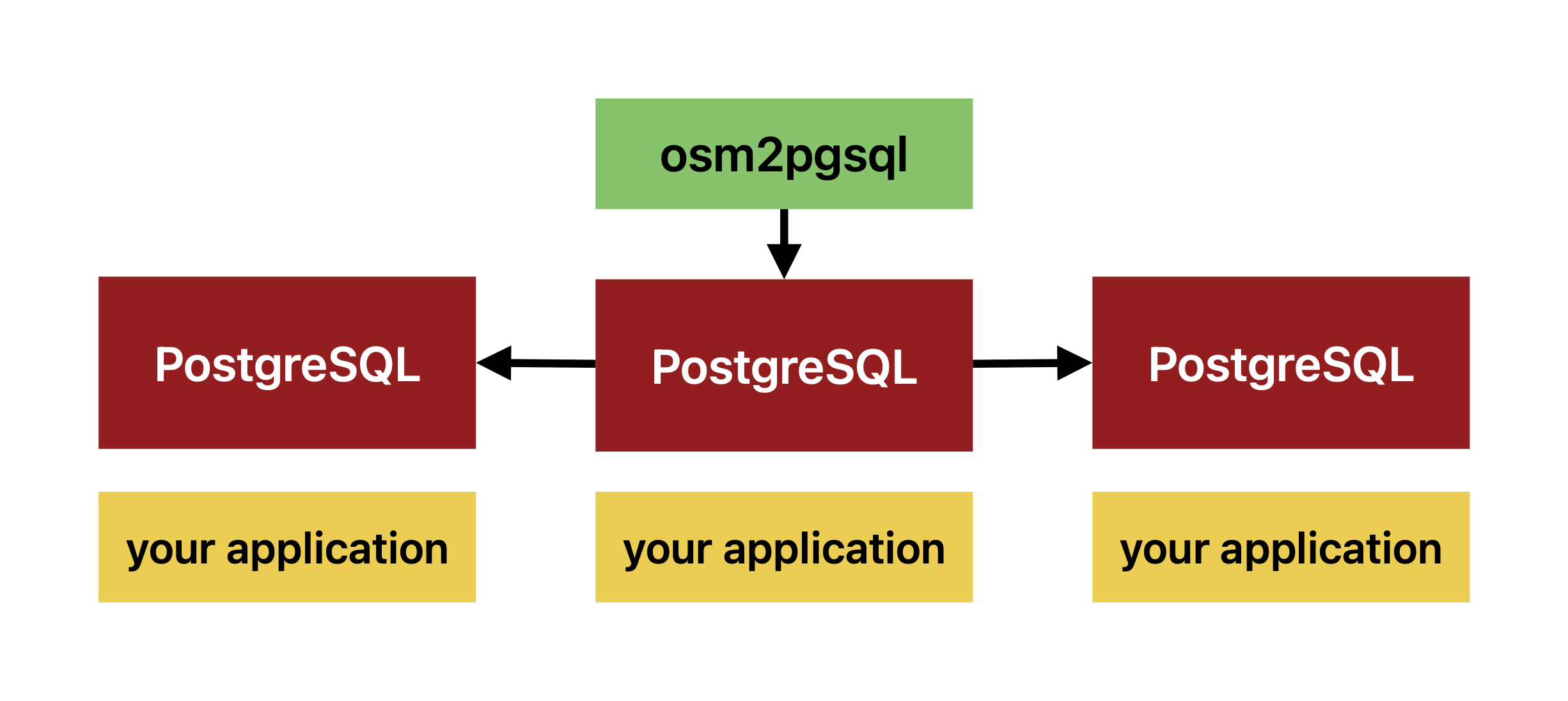
A better alternative is to run one osm2pgsql instance that performs the initial import and continuous updates while all other PostgreSQL instances are read replicas. This can be performed using the built-in logical replication, which started shipping with PostgreSQL 10.
This offloads the update process to one node, while all replicas get a preprocessed Postgres logical replication stream, just applying the data updates.
To get your database ready for replication, a few steps are required. In the following guide, we assume that you want to publish the tables containing points, lines, roads, and polygons, which are required for e.g. rendering using Mapnik.
1. Replica Identities
Logical replication propagates changes to the downstream databases at a high level. To be able to apply an UPDATE, it must be clear which rows this applies to. Since logical replication, as opposed to streaming replication, can be partial – not all tables or columns or even rows have to be replicated3 – this requires a row identity.
Usually, you can just use a PRIMARY KEY, which most tables have. Alas, this is not the case with a default osm2pgsql import. You can either add one using a flex config or do it yourself:
ALTER TABLE planet_osm_point ADD COLUMN id SERIAL PRIMARY KEY;
ALTER TABLE planet_osm_line ADD COLUMN id SERIAL PRIMARY KEY;
ALTER TABLE planet_osm_roads ADD COLUMN id SERIAL PRIMARY KEY;
ALTER TABLE planet_osm_polygon ADD COLUMN id SERIAL PRIMARY KEY;
Then you can indicate to PostgreSQL that you want to use these as replica identities:
ALTER TABLE planet_osm_point REPLICA IDENTITY DEFAULT;
ALTER TABLE planet_osm_line REPLICA IDENTITY DEFAULT;
ALTER TABLE planet_osm_roads REPLICA IDENTITY DEFAULT;
ALTER TABLE planet_osm_polygon REPLICA IDENTITY DEFAULT;
2. Publication
You can now mark these tables as available for replication. Make sure that your wal_level is sufficient: it must be set to logical in your postgresql.conf.4
To create the publication:
CREATE PUBLICATION osm_pub
FOR TABLE
planet_osm_point,
planet_osm_line,
planet_osm_roads,
planet_osm_polygon;
3. Prepare for Subscribing
The logical replication facility only copies data, not the schema. Therefore, you need to dump the schema for the tables you want to replicate and create it on your downstream nodes.
Get the schema from your upstream:
pg_dump \
-t planet_osm_point \
-t planet_osm_line \
-t planet_osm_roads \
-t planet_osm_polygon \
--schema-only > ddl.sql
Beware of TRIGGER and GRANT: these apply to your upstream but possibly not your read replicas.5 I use a little sed to remove them from the script:
sed -i '/^CREATE TRIGGER/ d' ddl.sql
sed -i '/^GRANT SELECT/ d' ddl.sql
Lastly, import the schema on your downstream(s):
psql -f ddl.sql
4. Subscribe
Your downstreams are ready to subscribe. You must be able to reach your upstream from your downstreams.
CREATE SUBSCRIPTION osm_sub
CONNECTION
'host=your.upstream.local port=... user=... password=... dbname=...'
PUBLICATION osm_pub;
PostgreSQL will start importing table by table into your replica and then keep up with updates. The initial import may take a while.
You can observe the process from your PostgreSQL log:
logical replication apply worker for subscription "osm_sub" has started
And the pg_subscription table:
SELECT * FROM pg_subscription;
oid | subdbid | subskiplsn | subname | subowner | subenabled | subbinary | substream | subtwophasestate | subdisableonerr | subpasswordrequired | subrunasowner | subfailover | subconninfo | subslotname | subsynccommit | subpublications | suborigin
-----+---------+------------+---------+----------+------------+-----------+-----------+------------------+-----------------+---------------------+---------------+-------------+-----------------------------------------------------------------------------------------+--------------------+---------------+-----------------+-----------
5555 | 1234 | 0/0 | osm_sub | 10 | t | f | f | d | f | t | f | f | host=10.1.1.2 port=5432 user=y password=x dbname=osm | osm_sub_1234 | off | {osm_pub} | any
(1 row)
If the upstream is unavailable, replication will pause and resume as soon as it becomes available again.
Closing Thoughts
I originally started writing this article five years ago when I first built this system, but I didn’t feel qualified enough to finalize it. The partners I built this with were much more experienced in streaming replication, but I stubbornly pushed for logical replication since the underlying mechanism has the aforementioned benefits and feels much more modern.
This approach definitely has drawbacks, too—most notably that you cannot promote a new upstream/primary, which is possible if you use streaming replication and something like repmgr. But since the database can be recreated at any point by just re-importing from source (which has the nice side-effect of getting rid of index bloat), this is quite acceptable in my opinion.
After shipping this to a customer, and also running it myself for multiple years, it has been running without adding any drama. I am only moonlighting as a DBA sometimes, so simple and effective solutions that don’t wake me up at 3 am are my favorites—and this is definitely one of those.
It must be noted that PostgreSQL is kind of a bad match for such workloads, and an OLAP-optimized DB would probably be a better fit, but PostGIS is extremely powerful when you want to work with geospatial data. I worked on geospatial systems that would make a database unnecessary, but losing access to PostGIS made that unfeasible – at least for my resources and skill level. ↩︎
Almost 100GB at the time of writing. ↩︎
If you already know exactly which tables or expressions you need on your replicas, you can restrict the data that will be published: adjust the
CREATE PUBLICATIONin section 2. ↩︎https://www.postgresql.org/docs/current/runtime-config-wal.html#RUNTIME-CONFIG-WAL-SETTINGS ↩︎
Triggers are used by osm2pgsql, but you do not need them on your read replicas, since these will not run the import/update process. Grants are for permissions, but your permission set on replicas may be different from the upstream. ↩︎